
RECUPERACIÓN DEL FALLO TECNOLÓGICO GLOBAL DE CrowdStrike PODRÍA SER UN PROCESO LARGO Y ARDUO
(CNN) — La compañía que causó una interrupción masiva de computadoras en todo el mundo dice que la actualización fallida fue revertida pero eso no necesariamente ayuda a las miles de empresas que se han visto afectadas por el fallo.
![]()

El problema del software CrowdStrike que causó el apagón afecta a un nivel tan profundo de los equipos y sistemas afectados que, en muchos casos, será un enorme desafío ponerlos en funcionamiento.
![]()
A esto se suma el hecho de que muchos de los servidores que pueden contener la información necesaria para que estos sistemas vuelvan a funcionar están atrapados en un ciclo de fallos y reinicios.
Y puede que ni siquiera sea fácil acceder a algunas de las computadoras afectadas, instaladas en ubicaciones remotas y pensadas para funcionar sin intervención humana.
«No creo que sea demasiado pronto para decirlo: este será el mayor apagón informático de la historia», afirmó el experto en seguridad Troy Hunt en una publicación en X.
El software de CrowdStrike en cuestión opera en lo que se denomina el nivel del kernel de un equipo, un nivel mucho más profundo que el de las aplicaciones más comunes, como los navegadores o los videojuegos. Esta parte de un dispositivo tiene mucha más visibilidad y control sobre una computadora y sus componentes, por lo que es fundamental para el funcionamiento de todos los demás sistemas, y mucho más sensible.

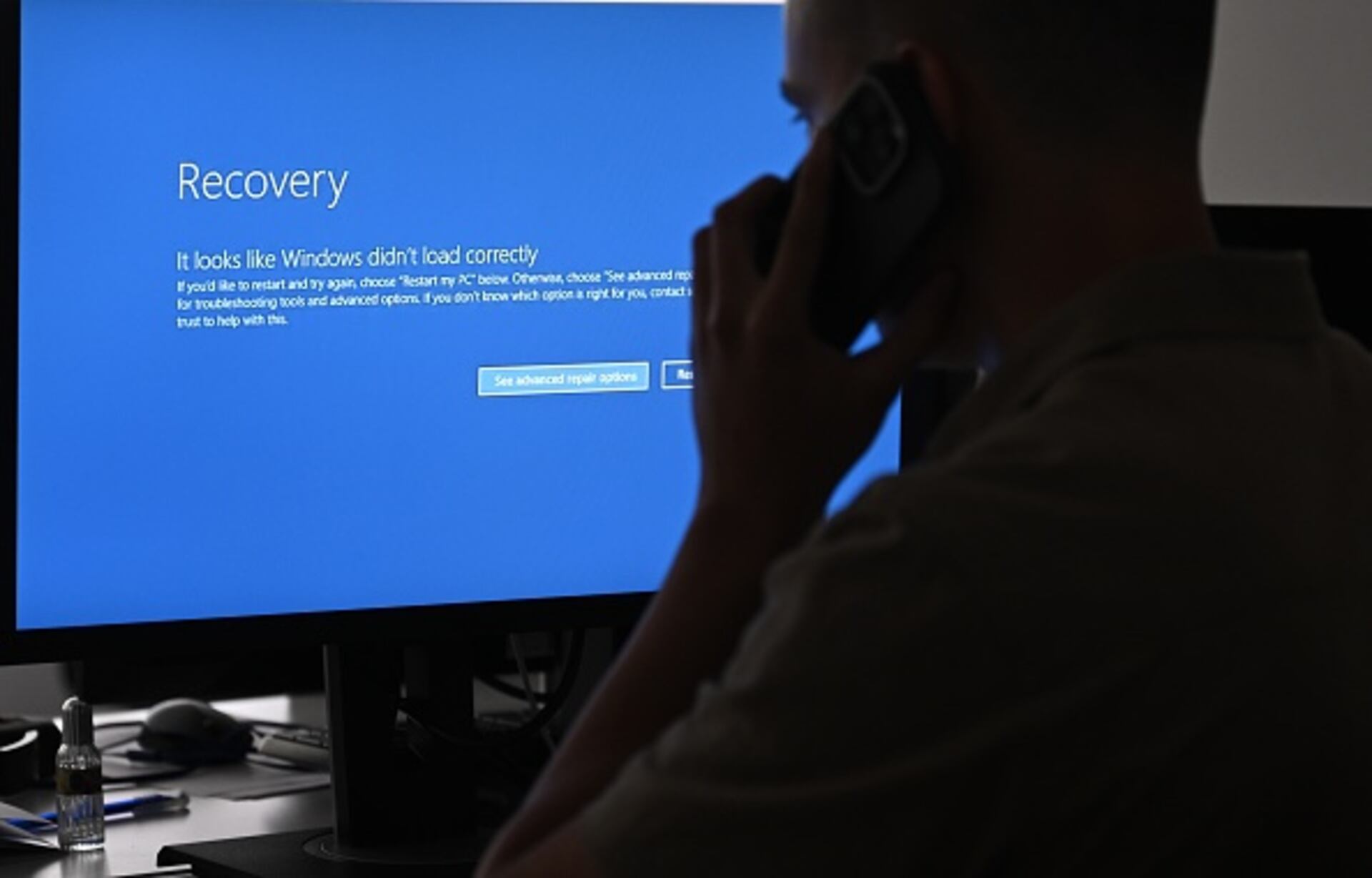
Funcionar a nivel del kernel significa que el software de CrowdStrike puede hacer más para detectar ciberataques, pero también significa que el fallo actual está provocando que las computadoras que corren Windows se bloqueen en una pantalla azul de la muerte antes de que los usuarios puedan tomar ninguna medida para corregirlo.
El problema parece ser recuperable, según CrowdStrike, pero en muchos casos requiere un trabajo minucioso: un administrador debe acceder a cada dispositivo afectado y reiniciarlo manualmente en modo seguro. A continuación, el archivo de CrowdStrike defectuoso debe borrarse a mano.
Para las empresas con cientos o miles de portátiles, equipos de escritorio y servidores que ejecutan el software de seguridad de CrowdStrike, un humano individual puede tener que realizar ese proceso una y otra y otra vez.
«No se puede automatizar eso», dijo Kevin Beaumont, investigador de seguridad y exanalista de amenazas de Microsoft, en un mensaje en X. «Así que esto va a ser increíblemente doloroso para los clientes de CrowdStrike».
El viernes, una página de estado de Microsoft informó que algunos usuarios de Windows Virtual Machine se han recuperado con éxito del problema reiniciando repetidamente, en algunas situaciones hasta 15 veces seguidas.
«Hemos recibido comentarios de los clientes que indican que pueden ser necesarios varios reinicios (se han notificado hasta 15), pero la opinión general es que los reinicios son un paso eficaz para la solución de problemas en esta etapa», dijo Microsoft en la página. La empresa no especuló sobre por qué la técnica parece funcionar.
Las organizaciones afectadas también pueden intentar restaurar sus máquinas a un estado anterior volviendo a una copia de seguridad del sistema anterior, añadió Microsoft, aunque reconoció que puede no ser posible en todos los casos.
«Las empresas que no han invertido en soluciones rápidas de copia de seguridad están atrapadas en un callejón sin salida», dijo Eric O’Neill, experto en ciberseguridad y ex funcionario de contrainteligencia del FBI.
Y se pone peor.

Las organizaciones que se toman en serio la seguridad probablemente habrán cifrado los discos duros de los equipos, lo que dificulta aún más el acceso al archivo que debe eliminarse.
Para esas organizaciones, «es necesario descifrar manualmente el disco con una clave de recuperación de BitLocker, que probablemente, para la mayoría de las empresas, está almacenada digitalmente en uno de los servidores que se está iniciando una y otra vez», dijo Ira Bailey, un investigador de seguridad, en una publicación en BlueSky.
Cada equipo afectado que esté cifrado con BitLocker tendrá que ser desbloqueado con una clave de recuperación antes de que las organizaciones puedan iniciar el proceso de eliminación del archivo CrowdStrike dañado y restaurar el funcionamiento normal, dijo el experto en ciberseguridad que se hace llamar SwiftOnSecurity en una publicación en X.
La recuperación será enormemente costosa para las empresas de Fortune 500 con grandes equipos de personal informático y probablemente aún más difícil para las empresas más pequeñas, dijo a CNN Kenn White, un investigador de seguridad independiente especializado en seguridad de redes.
«Si no tienes personal físico que pueda tocarlo, a gran parte de las empresas estadounidenses les va a costar muchos, muchos días recuperarse», dijo White. «Es simplemente una tonelada de trabajo manual intensivo».
«Es un procedimiento bastante complicado para personas no técnicas», añadió White, «e incluso a muchos profesionales de TI cualificados les resultará difícil hacerlo a la escala que se va a requerir dado el número de máquinas afectadas».
¿Cómo pudo el fallo de CrowdStrike tener efectos tan generalizados?

Dado que el software de seguridad de CrowdStrike se ejecuta en innumerables equipos individuales de todo el mundo, la actualización que se envió a esos dispositivos hizo que todos se apagaran, prácticamente al mismo tiempo.
Y en la economía en red de hoy en día, una interrupción en una parte de la cadena de suministro puede causar efectos dominó en toda la cadena. Cuando se caen varias partes de una cadena de suministro, se desencadena una cascada de problemas.
Imaginemos a una persona que intenta comprar un café, explica Andrew Peck, experto en ciberseguridad de la Universidad británica de Loughborough. Lo que puede parecer una transacción sencilla depende de múltiples computadoras que trabajan en tándem, desde el punto de venta de la cafetería hasta los propios sistemas back-end del procesador de pagos.
«Hay muchas computadoras en esta cadena y, normalmente, cuanto mayor es el negocio, mayor es la cadena», explica Peck. «Si alguna de las computadoras de la cadena no funciona, la transacción no se completará».
Según O’Neill, ex agente de contrainteligencia del FBI, arreglar todas las computadoras afectadas podría requerir millones de horas de trabajo de los profesionales informáticos de las empresas. Sin embargo, dijo, es difícil hacer una estimación firme porque se desconoce cuántas computadoras se vieron afectadas.
Imaginemos algo como la enorme industria de la aviación, el crítico sector de los servicios financieros o las operaciones de vida o muerte de un proveedor de atención sanitaria, y el alcance del desastre se hace evidente.
:quality(85)/cloudfront-us-east-1.images.arcpublishing.com/infobae/47EHQACTBW46URMAZUWGNREKPQ.jpg)
Ahora que mucha gente trabaja desde casa, los informáticos no pueden limitarse a ir de una mesa a otra para reparar las computadoras. En cambio, tendrán que comunicarse con cada empleado y explicarle el proceso a distancia.
«Esto agrava el problema», afirma. «Algo que podría haberse arreglado en horas va a tardar días».
Es posible que algunas máquinas afectadas apenas tengan personal de mantenimiento o estén situadas en zonas remotas. Otras pueden incluso no tener monitores o teclados conectados, porque no requieren regularmente que los humanos interactúen directamente con ellas.
Los ejemplos más extremos pueden incluir sensores de control meteorológico o dispositivos en cajas de señales ferroviarias, dijo Peck, lo que podría requerir que los técnicos visiten físicamente potencialmente cientos de miles de máquinas para llevar a cabo el proceso de recuperación.
La recuperación costará al mundo «miles de horas y millones, potencialmente miles de millones de dólares», dijo Peck, lo que rápidamente se suma a «algunos equipos de soporte de TI muy agotados quemando presupuesto que no tenían».
¿Cuál es el papel de Microsoft en todo esto?